
Mais gratuitement. Et puis sans le savoir. A l'insu de ton plein gré, comme on disait y a dix ans pour montrer qu'on avait de l'humour.
{kind=link}
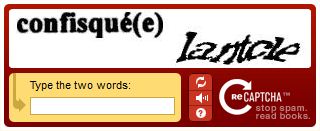
Facile, suffit d'utiliser des captcha de chez ReCaptcha (comme celui qui illustre ce post).
Pourquoi ? J'm'en va t'expliquer ça après la suite, ami lecteur...
En 2007, des scientifiques de l'université Carnegie Mellon ont eu une bonne idée, c'est d'utiliser les petits captcha pour faire de la reconnaissance de caractères. Le principe est simple : un des deux mots demandés est connu, l'autre est un mot issu d'un texte scanné que l'ordinateur n'a pas réussi à identifier. Quand suffisamment d'utilisateurs ont répondu la même chose au captcha, le mot est considéré connu, renseigné dans la base, et on passe au suivant. Malin, et très efficace. Ils ont appelé leur programme ReCaptcha, et ça devait contribuer au savoir mondial, tout ça tout ça, un truc noble, en témoignent les articles de l'époque.
Septembre 2009, patatras, les gars de ReCaptcha se sont sans doute dit que bosser pour la gloire c'était gentil, mais bon, un truc qui fonctionne aussi bien, autant se faire du bon pognon sonnant et trébuchant avec, alors ils vendent à Google, qui s'en félicite aussitôt.
Résultat – personne ne l'a caché mais comme personne n'en parle non plus, c'est kif kif –, quand vous renseignez un captcha sur un site, vous aidez Google Books à numériser son fonds.
Le problème ? Oh, trois fois rien, juste que dans sa grande quête hégémonique, Google numérise tout ce qui lui passe sous la main sans se soucier de qui est l'auteur, l'éditeur, les droits... Je veux pas donner l'impression de défendre le système des droits d'auteurs, juste pointer que eux, ils s'en foutent.
En France, Google Books est en procès avec tout un paquet d'éditeurs, et leurs avocats ont notamment utilisé des arguments comme : la justice française n'est pas compétente puisque la numérisation a lieu aux Etats-Unis, ou déclaré des gentillesses comme "Ce que fait Google est absolument légal. Nous n'avons jamais nié que les
Éditions du Seuil détiennent les droits sur les œuvres papier, mais
elles n'ont jamais prouvé qu'elles avaient les droits sur les versions
numériques de ces œuvres"...
En 2008, du temps où c'était mieux avant, les universitaires publiaient dans Science et estimaient pouvoir numériser 160 livres par jour avec leur système (PDF ici).
Et un des corollaires c'est que souvent seul le premier mot marche. Pour le deuxième vous pouvez mettre n'importe quoi vu que personne n'est sûr du résultat.
RépondreSupprimerJe sens que je vais carburer au corollaire, juste par pur esprit franchouillard...
RépondreSupprimer